Vad är webbskrapning? Hur man samlar in data från webbplatser
Annons
Webskrapare samlar automatiskt in information och data som vanligtvis endast är tillgängliga genom att besöka en webbplats i en webbläsare. Genom att göra detta autonomt öppnar webbskrapningsskript en värld av möjligheter inom data mining, dataanalys, statistisk analys och mycket mer.
Varför webbskrotning är användbart
Vi lever i en dag och en ålder där information är mer lättillgänglig än någon annan tid. Den infrastruktur som används för att leverera just dessa ord som du läser är en ledning för mer kunskap, åsikter och nyheter än någonsin har varit tillgängligt för människor i människors historia.
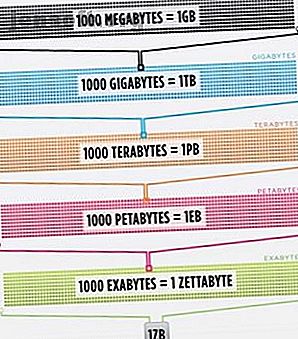
Så mycket att faktiskt att den smartaste personens hjärna, förbättrad till 100% effektivitet (någon borde göra en film om det), fortfarande inte skulle kunna hålla 1/1000-del av data lagrade på internet i USA ensam .
Cisco uppskattade 2016 att trafiken på internet överskred en zettabyte, vilket är 1 000 000 000 000 000 000 byte, eller en sextillion byte (gå vidare, fnissar på sextillioner). En zettabyte är ungefär fyra tusen år med strömmande Netflix. Det skulle motsvara om du, ofarlig läsare, skulle strömma kontoret från början till slut utan att stoppa 500 000 gånger.

All denna information och information är mycket skrämmande. Inte allt är rätt. Inte mycket av det är relevant för vardagen, men fler och fler enheter levererar denna information från servrar runt om i världen rätt till våra ögon och till våra hjärnor.
Eftersom våra ögon och hjärnor inte riktigt kan hantera all denna information, har webbskrapning framkommit som en användbar metod för att samla in data programmatiskt från internet. Webskrapning är den abstrakta termen för att definiera handlingen för att extrahera data från webbplatser för att spara det lokalt.
Tänk på en typ av data och du kan antagligen samla in den genom att skrapa webben. Fastighetslistor, sportdata, e-postadresser till företag i ditt område och till och med texterna från din favoritartist kan alla sökas och sparas genom att skriva ett litet manus.
Hur får en webbläsare webbdata?
För att förstå webbskrapare måste vi förstå hur webben fungerar först. För att komma till den här webbplatsen, skrev du antingen "makeuseof.com" i din webbläsare eller så klickade du på en länk från en annan webbsida (berätta var, på allvar vi vill veta). Hursomhelst är nästa par steg samma.
Först tar din webbläsare webbadressen du angav eller klickade på (Pro-tip: håll muspekaren över länken för att se URL-adressen längst ner i webbläsaren innan du klickar på den för att undvika att bli punkad) och bilda en "begäran" att skicka till en server. Servern kommer sedan att behandla begäran och skicka ett svar tillbaka.
Serverns svar innehåller HTML, JavaScript, CSS, JSON och annan information som behövs för att din webbläsare ska kunna bilda en webbsida för ditt tittande nöje.
Inspekterar webbelement
Moderna webbläsare tillåter oss vissa detaljer angående denna process. I Google Chrome på Windows kan du trycka på Ctrl + Shift + I eller högerklicka och välja Inspektera . Fönstret visar sedan en skärm som ser ut som följande.

En fliklista med alternativ raderar överst i fönstret. Av intresse just nu är fliken Nätverk . Detta kommer att ge detaljer om HTTP-trafiken som visas nedan.

I det nedre högra hörnet ser vi information om HTTP-begäran. URL: n är vad vi förväntar oss, och "metoden" är en HTTP "GET" -förfrågan. Statuskoden från svaret listas som 200, vilket betyder att servern såg begäran som giltig.
Under statuskoden finns fjärradressen, som är den allmänna IP-adressen för makeuseof.com-servern. Klienten får den här adressen via DNS-protokollet Varför ändra DNS-inställningar ökar din Internethastighet Varför ändra DNS-inställningar ökar din Internethastighet Att ändra dina DNS-inställningar är en av de mindre tweaks som kan få stora avkastningar på dagliga internethastigheter. Läs mer .
Nästa avsnitt visar detaljer om svaret. Svarhuvudet innehåller inte bara statuskoden utan också typen av data eller innehåll som svaret innehåller. I det här fallet tittar vi på “text / html” med en standardkodning. Detta säger oss att svaret bokstavligen är HTML-koden för att återge webbplatsen.

Andra typer av svar
Dessutom kan servrar returnera dataobjekt som svar på en GET-begäran istället för bara HTML för webbsidan att återge. En webbplatss applikationsprogrammeringsgränssnitt (eller API) Vad är API: er och hur ändrar öppna API: er Vad är API: er och hur ändrar öppna API: er Har du någonsin undrat hur program på din dator och webbplatserna du besöker "prata" till varandra? Läs mer använder vanligtvis denna typ av utbyte.
Genom att titta på fliken Nätverk som visas ovan kan du se om det finns den här typen av utbyte. När man undersöker CrossFit Open Leaderboard visas begäran om att fylla tabellen med data.

Genom att klicka över till svaret visas JSON-data istället för HTML-koden för att rendera webbplatsen. Data i JSON är en serie etiketter och värden i en skiktad, skisserad lista.

Att manuellt analysera HTML-kod eller gå igenom tusentals nyckel- / värdepar av JSON är mycket som att läsa Matrix. Vid första anblicken ser det ut som gibberish. Det kan finnas för mycket information för att manuellt avkoda den.
Webskrapare till undsättning!
Innan du begär den blåa pillen för att få häcken härifrån, bör du veta att vi inte behöver avkoda HTML-kod manuellt! Okunnighet är inte lycklig, och den här biffen är läcker.
En webbskrapa kan utföra dessa svåra uppgifter åt dig. Scrapestack API gör det enkelt att skrapa webbplatser för data. Scrapestack API gör det enkelt att skrapa webbplatser för data Letar du efter en kraftfull och prisvärd webbskrapa? Scrapestack API är gratis att starta och erbjuder många praktiska verktyg. Läs mer . Skrapningsramar finns på Python, JavaScript, Node och andra språk. Ett av de enklaste sätten att börja skrapa är att använda Python och vackra soppa.
Skrapa en webbplats med Python
Att komma igång tar bara några koder, så länge du har Python och BeautifulSoup installerat. Här är ett litet skript för att få en webbplats källa och låta BeautifulSoup utvärdera den.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Mycket enkelt gör vi en GET-förfrågan till en URL och sätter sedan svaret i ett objekt. Att skriva ut objektet visar HTML-källkoden för URL: n. Processen är precis som om vi manuellt gick till webbplatsen och klickade på Visa källa .
Specifikt är detta en webbplats som publicerar träning i CrossFit-stil varje dag, men bara en per dag. Vi kan bygga vår skrapa för att få träningen varje dag och sedan lägga till den i en sammanlagd lista över träningspass. I huvudsak kan vi skapa en textbaserad historisk databas med träningspass som vi enkelt kan söka igenom.
Magin med BeaufiulSoup är förmågan att söka igenom all HTML-kod med den inbyggda findAll () -funktionen. I detta specifika fall använder webbplatsen flera taggar för "sqs-block-content". Därför måste skriptet gå igenom alla dessa taggar och hitta den som är intressant för oss.
Dessutom finns det ett antal
taggar i avsnittet. Skriptet kan lägga till all text från var och en av dessa taggar till en lokal variabel. För att göra detta lägger du till en enkel slinga i skriptet:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! En webbskrapa föds.
Skala upp skrapning
Det finns två vägar för att gå framåt.
Ett sätt att utforska webbskrotning är att använda redan byggda verktyg. Web Scraper (bra namn!) Har 200 000 användare och är enkelt att använda. Parse Hub tillåter också användare att exportera skrapad data till Excel och Google Sheets.
Web Scraper tillhandahåller dessutom en Chrome-plugin som hjälper till att visualisera hur en webbplats byggs. Bäst av allt, att döma efter namn, är OctoParse, en kraftfull skrapa med ett intuitivt gränssnitt.
Slutligen, nu när du känner till bakgrunden för webbskrotning, höja din egen lilla webbskrapa för att kunna krypa och köra Hur man bygger en grundläggande webbcrawler för att dra information från en webbplats Hur man bygger en grundläggande webcrawler för att dra information från en webbplats Webbplats Har du någonsin velat fånga information från en webbplats? Du kan skriva en sökrobot för att navigera på webbplatsen och extrahera precis vad du behöver. Läs mer på egen hand är en rolig strävan.
Utforska mer om: Python, webbskrapning.

